
Traditionally, journal subject classification was done manually at varying levels of granularity, depending on the use case for the institution. Subject classification is done to help collate resources by subject enabling the user to discover publications based on different levels of subject specificity. It can also be used to help determine where to publish and the direction a particular author may be pursuing in their research if one wants to track where their work is being published. Currently, most subject classification is done manually as it is a speciality that requires a lot of training. However, this effort can be siloed by institution or can be hampered by various inter-institutional agreements that prevent other resources from being classified. It could also prevent a standardized approach to classifying items if different publications in separate institutions use different taxonomies and classification systems. Automating classification work surfaces questions about the relevance of the taxonomy used, the potential bias that might exist, and the texts being classified. Currently, journals are classified using various taxonomies and are siloed in many systems, such as library databases or software for publishers. Providing a service that can automatically classify a text (and provide a measure of accuracy!) outside of a specific system can democratize access to this information across all systems. Crossref infrastructure enables a range of services for the research community; we have a wealth of metadata created by a very large global community. We wondered how we could contribute in this area.
In our own metadata corpus, we had subject classifications for a subset of our journals provided by Elsevier. However, this meant that we were providing subject information unevenly across our metadata. We wondered if we could extrapolate the information and provide the data across all our metadata.
We looked specifically at journal-level classification instead of article-level classification for a few reasons. We had the training data for journal-level subject classification; it was a good place to begin understanding what would be needed. Our work so far provides a foundation for further article-level classification - if Crossref decides to investigate further.
To start with, I used Elsevier’s All Science Journal Classification Codes (ASJC), which have been applied to their database of publications, which includes journals and books. We used ASJC because it contained metadata that could be parsed programmatically. If the project progressed well, we felt that we could look at other classification systems.
After pre-processing, three methods (tf-idf, Embeddings, LLM) were used, and their performances were benchmarked. The following outlines the steps taken for the pre-processing, cleaning, and implementation details of the methods used to predict the subject classification of journals.
Pre-processing of data
The Excel document was processed as a CSV file and has various information, including journal titles, the corresponding print and e- ISSNs, and their ASJC codes. The journals were mostly in English but were also in many other languages, such as Russian, Italian, Spanish, Chinese, and others. First, there was a process to see which journals in the Elsevier list also existed in the Crossref corpus. As of June 2022, there were 26,000 journals covered by the Elsevier database. The journals could contain one or many subject categories. For example, the Journal of Children’s Services has several subjects assigned to them, such as Law, Sociology and Political Science, Education, and Health. The journal titles have some data, but not a lot. They averaged about four words per title, so more data was needed. First, 10 - 20 journal article titles per journal were added if there were that many journal articles available. At Crossref, a few journal articles contain abstracts, but not all. So, for the moment, journal titles and their corresponding article titles were the additional data points that were used.
Cleaning the data
The data was cleaned up to remove stop words, various types of formulae, and XML from the titles. Stop words generally consist of articles, pronouns, conjunctions, and other frequently used words. The stop words list of all languages in the ISO-639 standard was used to process the titles. Some domain-specific terms to the stop words, such as “journal”, “archive”, “book”, “studies”, and so on, were also added to the list. Formulae and XML tags were removed with regular expressions. Rare subject categories that were assigned to very few journals (less than 50 out of 26000 journals) were also removed. The cleaned data was now ready for processing. It was split into training, validation, and test sets.
Methods
This particular type of classification is known as a multi-label classification problem since zero, or many subjects can be assigned to a journal. Three methods were used to see which performed best.
TF-IDF + Linear Support Vector Classification
The first approach used the tf-idf and multilabel binarizer libraries from scikit learn. Tf-idf is a numerical statistic that is intended to reflect how important a word is to a document in a collection. Using tf-idf, a number of different strategies that can be used within a multi-label classification problem were benchmarked. The tf-idf vectorizer and multilabel binarizer are Python libraries that convert data into machine parseable vectors. Essentially, the data is a table of journal and article titles and their corresponding subjects.
A baseline prediction was needed to benchmark the performance of the strategies used. This prediction was made by comparing the presence of the subject codes assigned to the journal with the most common subject codes present in the corpus. The measure used to compare the performances was the micro F1 score. The micro F1 score of the baseline prediction was 0.067. It shows that applying a naive approach will provide a prediction at 6.67% accuracy. That measure provided a good starting point to get an idea of the performance of subsequent methods.
Among the strategies used, the best-performing strategy was One vs Rest using LinearSVC. The micro F1 score was 0.43 after processing 20,000 features using the validation dataset. This was a decent increase from the baseline; however, it is still not very serviceable. In order to improve performance, it was decided to reduce the granularity of subjects. For example, the journal, Journal of Children’s Services, has several subjects assigned to them, such as Law, Sociology and Political Science', Education, and Health. Elsevier’s ASJC subjects are in hierarchies. There are several subgroups of fields within some overarching fields. For example, the group, Medicine, has several specialities of medicine listed under it. The subjects, Social Sciences and Psychology work similarly. They are two separate fields of study, and the journal has articles that apply to either or both fields of study. The subjects listed in the Journal of Children’s Services are in two different groups: Social Sciences and Psychology. Downgrading the granularity makes the learning process a little simpler. So, instead of the Journal of Children’s Services belonging to several different subjects, the journal now belonged to two subjects. Using the same strategy, one vs rest with LinearSVC, we get an F1 score of 0.72 for the same number of titles. This was a marked improvement from before. There were other avenues that could be looked at, such as bringing in more data in the form of references, but there were also other methods to look at. We were curious about the role of embeddings and decided to pursue that approach.
Embeddings + Linear Support Vector Classification
This approach is slightly different from the tf-idf approach. For the titles, we decided to use a model that was already trained on a scientific corpus. For this, AllenAI’s SciBERT was used, a fine-tuned BERT model trained on papers from the corpus of semanticscholar.org; a tool provided by AllenAI. The model provides an embedding: a vector representation of the titles, based on the data it has already been trained on. This allows it to provide more semantic weight on the data rather than simple occurrence of the words in the document (this occurs with the previous method, tf-idf). The generation of the embedding took over 18 hours on a laptop, but after that, generating predictions became quite fast. The amount of data needed to generate this vector is also lower than the tf-idf generation. The subjects were processed similarly to before and generated a vector using the multilabel binarizer. With 512 features from the titles (instead of 20,000) in the previous approach, the same strategy was used as earlier. Using the one vs rest strategy with LinearSVC the strategy was run against the validation set and got a F1 score of 0.71.
So far, the tally is:
| Method | F1 Score |
|---|---|
| Tf-idf + multilabel binarizer | 0.73 |
| SciBERT embedding + multilabel binarizer | 0.71 |
At this point, we were going to look into gathering more data points such as references and run a comparison between these two methods. However, large language models, especially ChatGPT, came into the zeitgeist, a few weeks into mulling over other options.
OpenAI: LLM + sentence completion
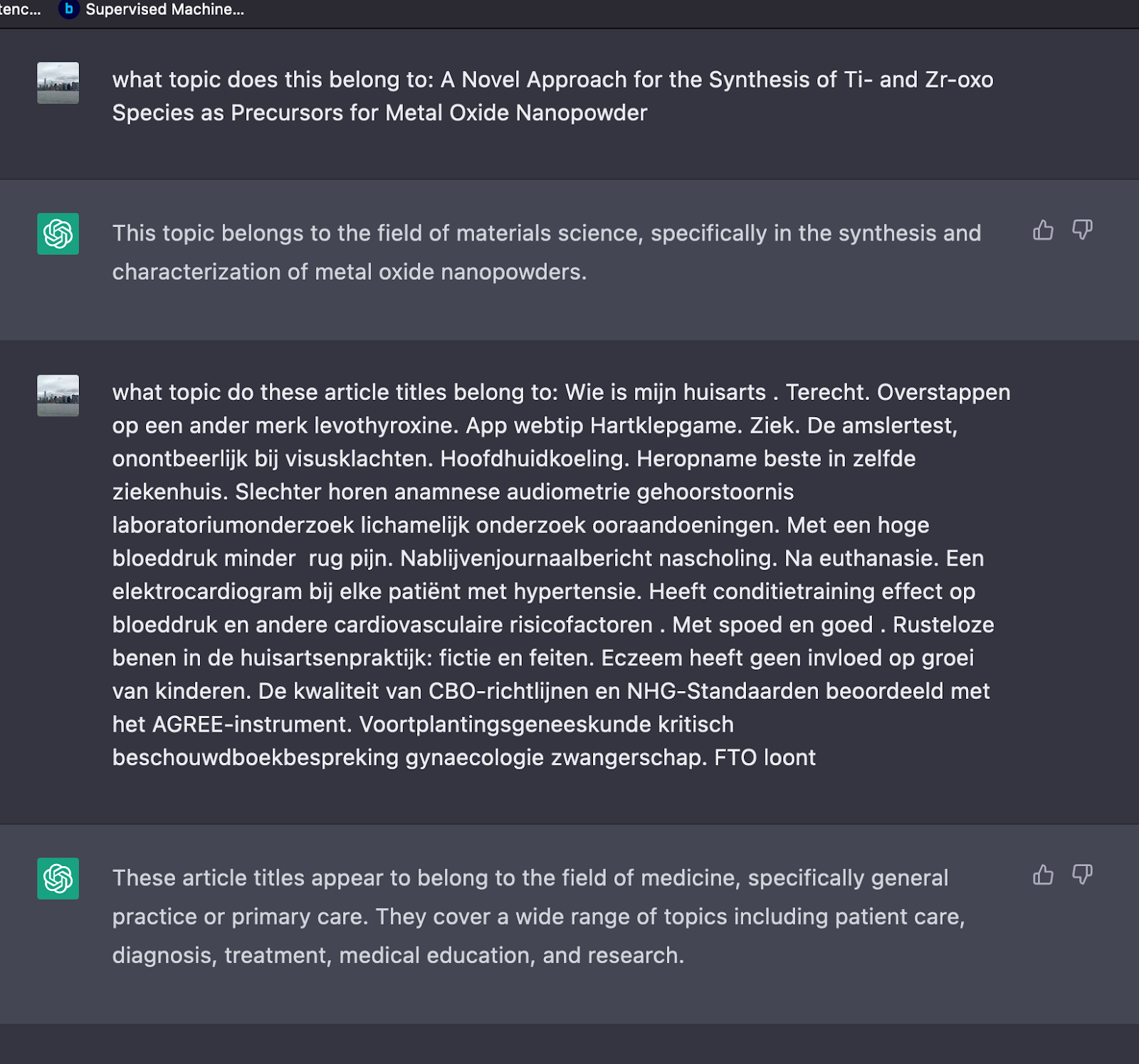
Out of curiosity, the author looked to see what chatGPT could do. ChatGPT was asked to figure out what topics an existing journal title belonged to, and it came very close to predicting the correct answer. The author also asked it to figure out to which topic multiple Dutch journal article titles belonged, and it predicted the correct answer again. The author decided to investigate this avenue knowing that if there were good results, open large language models would be used to see if there would be comparable results. The screenshot below shows the examples listed above.
Subjects had to be processed a little differently for this model. The ASJC codes have subjects in text form as well as numerical values. For example, if there is a journal classified as “Medicine”, it has a code of “27”. The author fine-tuned the openAI model using their “ada” model (it is the fastest and the cheapest) and sent it some sentence completion prompts. Essentially, this means that the model is being fine-tuned into telling it what subject codes it needs to complete the sentences that it is being sent. So, suppose several different titles are sent to the model and asked to complete it with several delimited subject codes. In that case, the model should be able to predict which subject codes should complete the sentences. A set of prompts were created with the journal titles and their corresponding subject codes as the sentence completion prompt to train the model. It looked like this:
{"prompt":"Lower Middle Ordovician carbon and oxygen…..,"completion":" 11\n19"}
The above snippet has several different titles where the subjects assigned to these titles are 11 and 19, which are Agricultural and Biological Sciences and Earth and Planetary Sciences, respectively.
The openAI’s API was used to fine-tune and train a model using the above prompts, and $10.00 later, generated a model.
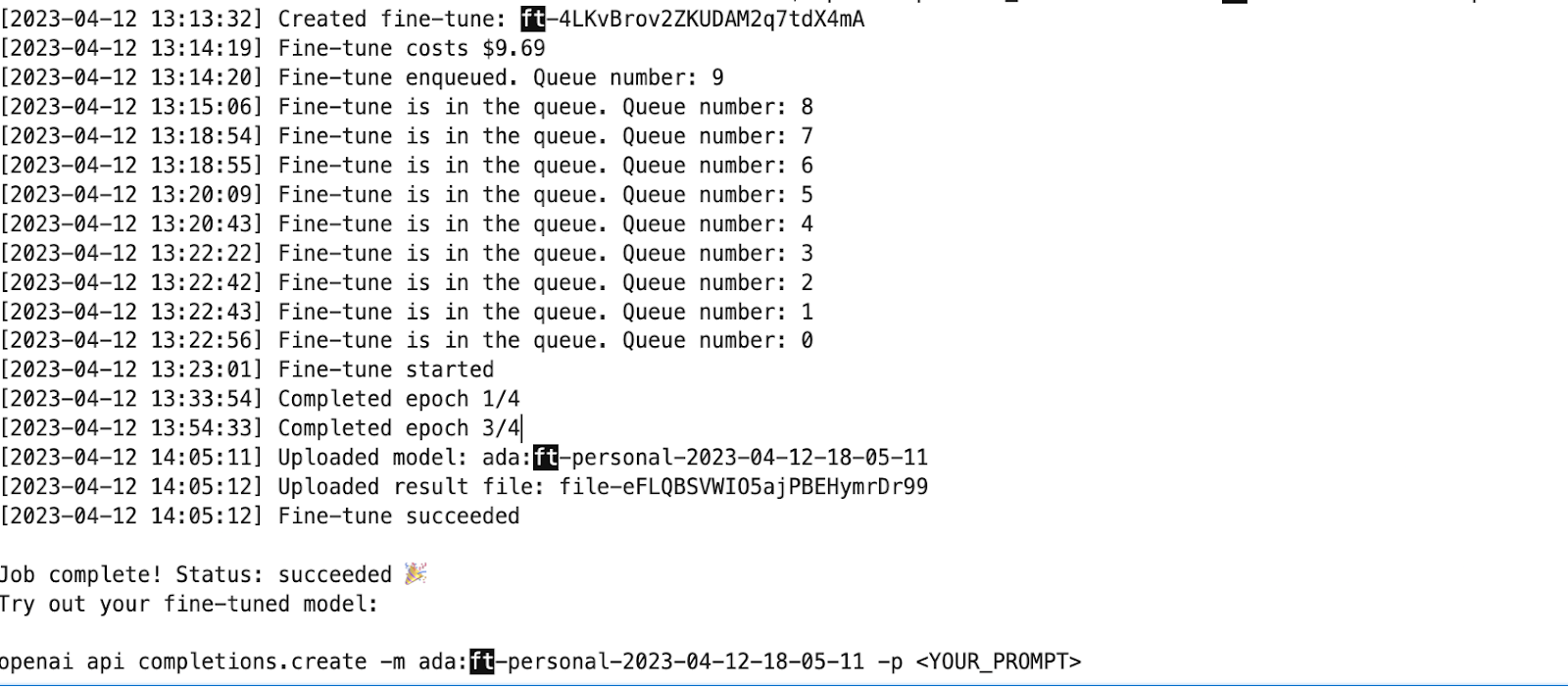
The validation dataset was run against the model and got a micro F1 score of 0.69. So, the tally now is:
| Method | F1 Score |
|---|---|
| Tf-idf + multilabel binarizer | 0.73 |
| SciBERT embedding + multilabel binarizer | 0.71 |
| ChatGPT + sentence completion | 0.69 |
Summary
So, sad trombone, using three different methods, the F1 score is similar across all three methods. Essentially, we needed more data for more accurate predictions. Crossref has abstracts for a subset of the deposited publication metadata. Therefore, this data could not be used at this time for comparison. However, having that data could possibly yield better results. The only way to do that is to use a similar method to get those results. We do not have that currently, and so, for now, it becomes a chicken and egg thought exercise. Getting even more data, such as full-text, could also produce interesting results, but we do not have the data for that either. For now, Crossref decided to remove the existing subject classifications that were present in some of our metadata. We could revisit the problem later - if we have more data. There are certainly interesting applications of these methods. We could:
- Look into topic clustering across our metadata and see what surfaces. This could also have applications in looking at the research zeitgeist across various time periods.
- Measure the similarities of embeddings with each other to look at article similarities, which could yield interesting results in recommendations and search.
Automated subject classification also raises questions about fairness and bias in its algorithms and training and validation data. It would also be productive to clearly understand how the algorithm reaches its conclusions. Therefore, any automated system must be thoroughly tested, and anyone using it should have a very good understanding of what is happening within the algorithm.
This was an interesting exercise for the author to get acquainted with machine learning and become familiar with some of the available techniques.
Copyright © 2023 Esha Datta. Distributed under the terms of the Creative Commons Attribution 4.0 License.







{kind=link}