
The development of practices and policies in support of data sharing has resulted in a growing number of open outputs being published every year. This has been followed by an increasing interest in understanding how open research objects are used, and efforts to track open science practices. An example of this is the Open Science Monitoring Initiative (OSMI), which has produced a list of monitoring efforts including for instance the national monitoring frameworks implemented in France and Japan. Datasets are a key element in open science monitoring, and there is strong interest across the research ecosystem in understanding and reporting data use and reuse: research funders are interested in evidence that datasets they funded advance research progress and benefit society, repositories want to report on the return on investment from their data collections, and meta-researchers want to study trends in use to build evidence and inform areas of need to advance open data.
In response to this community need, researchers and groups have started tracking the use and reuse of published data (see Federer, van de Sandt et al., or approaches by scholarly content providers). Different methodologies and frameworks are being applied, however, starting with how data ‘reuse’ is defined. So are we talking apples to apples when referring to data use? If we are to capture this information consistently for all stakeholders, in a format that makes this information actionable and potentially scalable via metadata, we need to recognize data use as a discrete function and apply a uniform structure for describing that usage. This was the motivation for creating the FORCE 11 Data Usage Typologies Working Group.
The Working Group brought together representatives with diverse expertise across the data ecosystem, including meta-researchers, librarians, institutional representatives, funders, and infrastructure providers, with two main goals: 1) to create a community-developed typology of data uses applicable across disciplines and sectors, along with characteristics that identify each use type, and 2) to recommend how to capture data use types in metadata. Such a typology provides a foundation for sustainably monitoring usage over time, comparing usage across sectoral contexts and domains, and recognizing those responsible for producing and providing data. This allows for consistent categorization of uses and supports incorporating data use considerations as part of assessments of research and societal impact.
During 2025, the Working Group focused on its first goal, and we are pleased to share the Typology of Data Uses that we have developed.
The Data Usage Typology
The Data Usage Typology is anchored on three dimensions of use:
Access - How is use enabled: through what tools and channels do users gain the ability to retrieve, modify, copy, and/or move data?
User - Who is using the data and in what role: what kind of disciplines, organizations and professions are involved?
Application - How are datasets used: for what purpose and outcomes, and what outputs are produced?
Each dimension consists of categories that provide further granularity for describing the use of data. Each category has a definition and associated values which the category can take. Values are derived from controlled vocabularies, either developed for the typology or building on existing vocabularies, e.g. for countries, research disciplines and outputs.

Our goal with this typology was to capture contextual information about the use of data, and key elements that inform understanding and insights about that use. We recognize that for a number of use situations, it will not be possible to complete all the elements of the typology: a researcher using a dataset they have created will likely have complete information, while a repository seeking to collect information about the use of datasets it hosts may have information for only some of the categories. With this in mind, we do not present items within the typology as mandatory, but rather propose it as a framework to bring structure to the contextual information that can be collected about data use, by different actors, and for diverse use types.
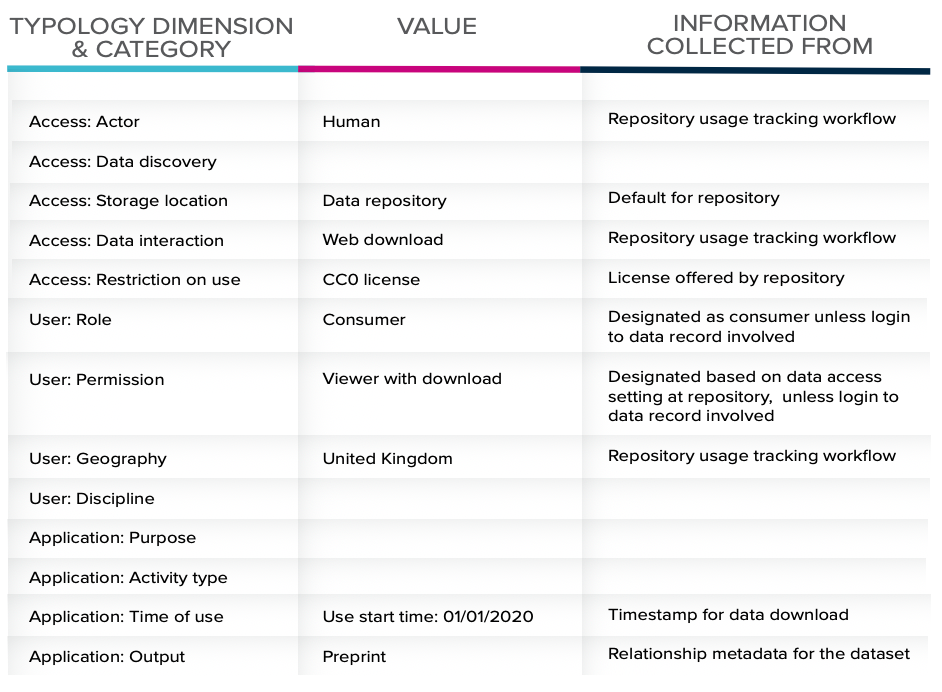
As an example of how the typology can be applied, let’s take a repository manager who seeks to understand how researchers interact with datasets at the repository, so that they can inform service improvements and maximize the utility of their data. The repository manager could map the information the repository collects via metadata and usage workflows to the typology to get structured insights into the use of the data:
A typology shaped by community input and open to refinement
The development of the typology was informed by rich discussions among the Working Group members. An important issue was how to address datasets that do not have an associated persistent identifier (PID). We acknowledge that when a dataset has a PID (generally a DOI or an accession number), the PID metadata facilitates capturing some of the information in the typology e.g., the connection between the dataset and an output. While we did not restrict the typology to data objects with PIDs, it is important to note that the typology was designed with digital data in mind. Application to analog data (e.g., samples) might be possible but it is likely that adjustments would have to be made to fully capture relevant properties of analog usage.
A central decision for the group to settle on was about defining when a specific instance of data usage had ended. After considering different options, the group agreed on the middle ground that the typology captures data usage for one entity interacting with the data in the User dimension, but at the same time all ways in which the data is used in the Application dimension. This ensures that downstream outputs are captured - e.g. an article based on a preprint, which is in turn based on a dataset - which are sometimes only indirectly linked to the dataset and can be the output by actors other than the initial one.
Artificial intelligence (AI) related to the use of data was another key topic in our discussions. AI is a significant emerging factor in both the use of data, and in generating data-usage information. The group decided not to incorporate this element directly in the typology as we felt that practices in this area are still developing, and that broader expertise in this area would be valuable.
An invitation for community feedback
We hope that this typology helps the community capture richer context about how data is used, in consistent ways that enable collection and comparison across different settings and evaluation needs. We invite community feedback on the typology and areas for refinement or further development. Please send us your comments and suggestions via this form.
As next steps, the Working Group will now explore recommendations for capturing data-use types in metadata, building on this typology. We will host a workshop about data usage and applications of this typology at the upcoming FORCE2026 conference, and look forward to discussing this work with the community.
References
- Federer, L. M. (2019). WHO, WHAT, WHEN, WHERE, AND WHY? QUANTIFYING AND UNDERSTANDING BIOMEDICAL DATA REUSE [Digital Repository at the University of Maryland]. https://doi.org/10.13016/60JD-9HUX
- Van De Sandt, S., Dallmeier-Tiessen, S., Lavasa, A., & Petras, V. (2019). The Definition of Reuse. Data Science Journal, 18, 22. https://doi.org/10.5334/dsj-2019-022
- Puebla, I., & Colangelo, E. (2025, December 2). Monitoring open science with scholarly content providers: What OSMI’s survey tells us. Upstream. https://doi.org/10.54900/5gjkq-ngh33
- Bobrov, E., Broadhurst, R., Byers, N., Erdmann, C., Genova, F., Hellström, M., Kemp, J., Puebla, I., & FORCE11 Data Usage Typologies Working Group (with Cadwallader, L., Cannon, M., Courtot, M., Dong, D., Edmunds, S., Ernest, E., Gautier, J., González López, J. B., Gregory, K., Guerreiro, M., Harrison, M., Heibi, I., Holmes, K., Jeangirard, E., Johnsson, M., Krishnan, A., Manghi, P., McKone, L., Medina-Smith, A., … Zakharov, W.). (2026). Typology of Data Uses: An output of the FORCE11 Data Usage Typologies Working Group. Zenodo. https://doi.org/10.5281/ZENODO.19184004
Copyright © 2026 Iratxe Puebla, Francoise Genova, Monica Morrison. Distributed under the terms of the Creative Commons Attribution 4.0 License.








{kind=link}