
Scholarly publishing is going through an exciting transition. Researchers are increasingly publishing their work on preprint servers before submitting it to journals. Some researchers have even decided not to submit to journals at all. On top of this, new forms of peer review are emerging, organized around preprints and operating independently from traditional journal peer review. Journals have started to reconsider their role in the scholarly publishing system, which has for instance led eLife to abandon accept/reject decisions. In addition, a growing number of research funders, including the funders behind Plan S, no longer expect researchers to publish their work in journals, recognizing that peer review can be organized just as well around preprints, without involving journals.
Bibliographic databases play a crucial role in scholarly literature discovery and research evaluation. How do these databases respond to the preprint revolution? The traditional focus of these databases has been on articles published in peer-reviewed journals, but this is gradually changing. For instance, in 2021, Scopus announced that it had started to index preprints. And earlier this month, Web of Science announced the launch of its Preprint Citation Index.
In this blog post, we discuss how preprints are indexed by different bibliographic databases and we present recommendations for optimizing the indexing of preprints.
Indexing of preprints in bibliographic databases
Our focus is on five popular bibliographic databases: Dimensions, Europe PMC, the Lens, Scopus, and Web of Science. Europe PMC and the Lens are freely accessible. Europe PMC has also adopted the Principles of Open Scholarly Infrastructure. Scopus and Web of Science require a subscription. Dimensions has a freely accessible version with limited functionality. A subscription is needed to access the full version. We take into account only information made available through the web interfaces of the various databases. Some databases may contain additional information that is not accessible through their web interface, but we do not consider such information.
Databases such as Crossref, OpenAlex, and OpenCitations do not have an easy-to-use web interface, making them less interesting for end users. We therefore do not discuss these databases. We do not consider Google Scholar either. While Google Scholar offers an important search engine for scholarly literature, the underlying database is hard to access. We also do not consider PubMed, since its indexing of preprints is still in a pilot phase.
Dimensions and the Lens both index preprints from a large number of preprint servers across all disciplines. In the case of the Lens, it is important to be aware that some preprints, in particular from arXiv and SSRN, incorrectly have not been assigned the publication type ‘preprint’. Europe PMC also covers a large number of preprint servers, but due to its focus on the life sciences, it does not index preprints from servers such as arXiv and SSRN (except for COVID-19 preprints). The recently launched Preprint Citation Index in Web of Science covers five preprint servers: arXiv, bioRxiv, ChemRxiv, medRxiv, and Preprints.org. A number of large preprint servers, including OSF Preprints, Research Square, and SSRN, are not (yet) covered by Web of Science. Scopus covers arXiv, bioRxiv, ChemRxiv, medRxiv, Research Square, SSRN, and TechRxiv. It does not (yet) index preprints from servers such as OSF Preprints and Preprints.org. Moreover, indexing of preprints in Scopus has two significant limitations: Preprints published before 2017 are not indexed, and preprints are not included in the document search feature in Scopus. Preprints are included only in the author profiles that can be found using the author search feature.
Challenges of indexing preprints
Indexing of preprints raises a number of challenges, which are addressed in different ways by the different bibliographic databases. We consider four challenges: version history, links to journal articles, links to peer reviews, and citation links.
A preprint may have multiple versions. Ideally a bibliographic database should present a version history. This enables users to see when the first version of a preprint was published and when the preprint was last updated. Europe PMC and Web of Science do indeed present version histories. The other databases do not provide this information.
Many articles are first published on a preprint server and then in a journal. Bibliographic databases should show the link between a preprint and the corresponding journal article. Dimensions, Europe PMC, and Web of Science show these links. The Lens and Scopus do not show them.
It is increasingly common for preprints to be peer reviewed outside the traditional journal peer review system. Peer review of preprints may take place on platforms such as Peer Community In, PeerRef, PREreview, and Review Commons. The reviews are typically made openly available. Several research funders have made a commitment to recognize peer-reviewed preprints in the same way as peer-reviewed journal articles. To support these developments, bibliographic databases should index not only preprints but also peer reviews and should link preprints to the corresponding reviews. None of the databases currently offer this feature. Europe PMC provides links from preprints to peer reviews, but these links refer to external platforms. Europe PMC itself does not index peer reviews. The Lens does index peer reviews, but the reviews are not linked to preprints.
Citation links represent another challenge. In its citation statistics, Scopus does not include citations given by preprints. The other databases do include such citations. This raises the issue of duplicate citations. When an article has been published both on a preprint server and in a journal, the preprint version of the article and the journal version will typically have a similar or identical reference list. A publication that is cited by the article may then receive two citations, one from the preprint version of the article and one from the journal version. None of the databases deduplicate such citations.
Recommendations for indexing preprints
In the box below, we present six recommendations for optimizing the indexing of preprints in bibliographic databases. As we will discuss later, implementing these recommendations requires close collaboration between bibliographic databases and other actors in the scholarly publishing system.
A bibliographic database should index preprints from all relevant preprint servers. A disciplinary database (e.g., PubMed and Europe PMC) should index preprints from all preprint servers relevant in a particular discipline. A multidisciplinary database (e.g., Dimensions, the Lens, Scopus, and Web of Science) should index preprints from all preprint servers across all disciplines.
Recommendation 2: Provide comprehensive preprint metadata.
A bibliographic database should provide metadata for preprints that is as comprehensive as metadata for journal articles. The metadata should at least include the title and abstract of a preprint, the names and affiliations of the authors, the reference list, and funding information. It should also include a version history.
Recommendation 3: Provide links between preprints and journal articles.
If an article has been published both on a preprint server and in a journal, a bibliographic database should provide a link between the preprint and the journal article. The link establishes that the preprint and the journal article are different versions of the same article. The preprint and the journal article belong to the same publication family.
Recommendation 4: Provide links between preprints and peer reviews.
If a preprint has been peer reviewed and the reviews have been made openly available, a bibliographic database should index the reviews and should provide links between the preprint and the reviews.
Recommendation 5: Provide deduplicated citation links between publication families.
A bibliographic database should provide deduplicated citation links at the level of publication families. If there are multiple citation links from publications in one publication family (e.g., from a preprint and from a journal article) to publications in another publication family, these citation links should be deduplicated.
Recommendation 6: Do not make arbitrary distinctions between publication types (preprints, journal articles, and others).
A bibliographic database should not make arbitrary distinctions between preprints, journal articles, and other publication types. A database may inform its users about relevant differences between publications of different types (e.g., whether publications have been peer reviewed or not), but otherwise it should treat all publications in the same way, regardless of their publication type.
The table below summarizes the extent to which different bibliographic databases meet our six recommendations. Two stars are awarded if a database fully meets a recommendation, one star is awarded if a recommendation is partly met, and no stars are awarded if a recommendation is not met at all.
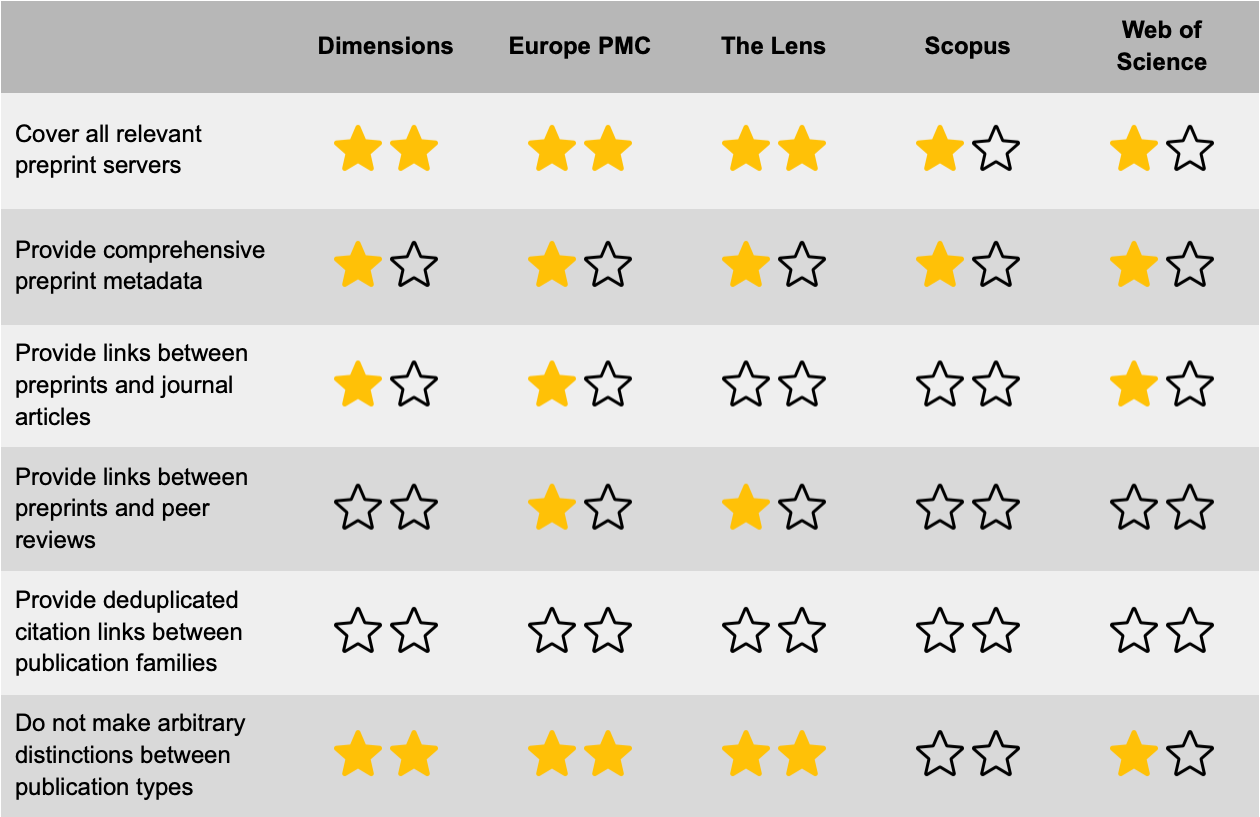
Dimensions, Europe PMC, and the Lens seem to cover all relevant preprint servers, resulting in two stars for the first recommendation. We have awarded one star to Scopus and Web of Science. They still need to work on improving their coverage of preprint servers. Web of Science informed us that in the coming year it expects to substantially increase the number of preprint servers it covers.
None of the bibliographic databases provide comprehensive preprint metadata. The databases make available basic metadata fields such as the title, abstract, and publication date of a preprint as well as the names of the authors. Sometimes they also provide more advanced metadata fields, for instance the reference list, author affiliations, and funding information, but in many cases these metadata fields are missing. Based on some spot checking, our impression is that each database has its own strengths and weaknesses in terms of the completeness of preprint metadata. For instance, while some databases provide more comprehensive metadata for arXiv preprints, others do a better job for bioRxiv preprints. In general, metadata seems to be more complete for recent preprints than for older ones. Since all databases suffer from gaps in their preprint metadata, we have awarded one star to each of them. As we will discuss below, improving the availability of preprint metadata is a joint responsibility of bibliographic databases and preprint servers.
The Lens and Scopus do not provide links between preprints and journal articles, although the Lens told us that they are working on providing such links. Dimensions, Europe PMC, and Web of Science do provide links between preprints and journal articles. However, because the links seem to be incomplete, we have awarded only one star to these databases.
Europe PMC is the only database that provides links from preprints to peer reviews, but it does not index the reviews. We have therefore awarded one star to Europe PMC. We have also awarded one star to the Lens. While the Lens does not provide links between preprints and peer review, it does index reviews in its database.
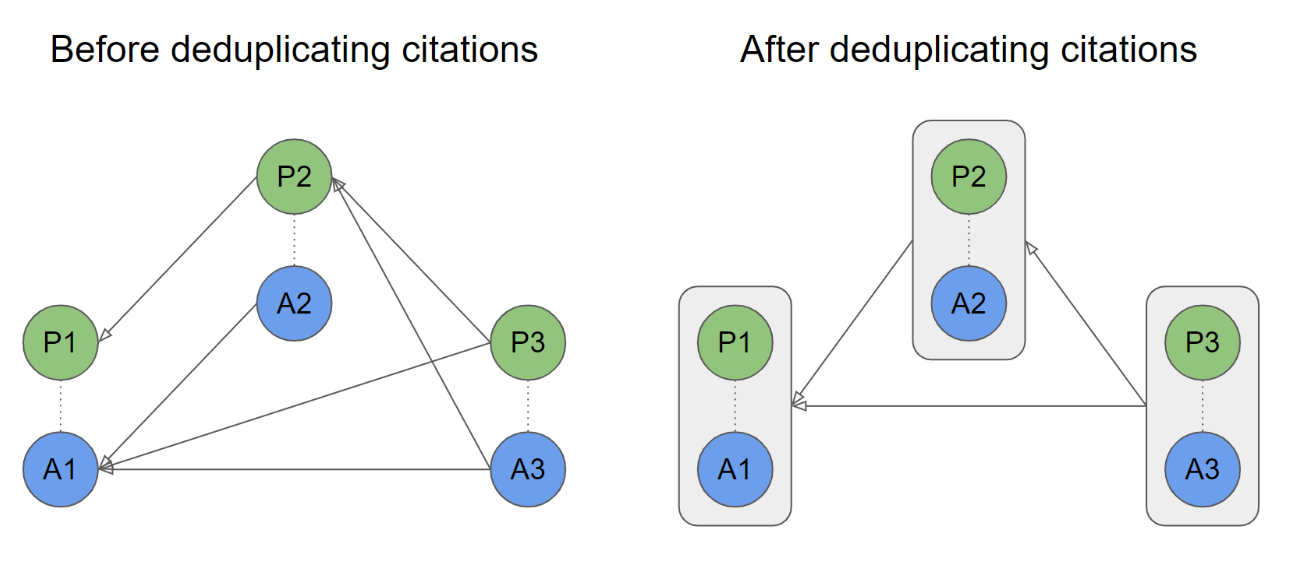
The figure below illustrates the idea of deduplicating citation links. There are three publication families, each consisting of a preprint (in green) and a corresponding journal article (in blue). Before deduplication, there are six citation links. After removing duplicate citation links between publication families, only three citation links are left. Of the five bibliographic databases considered in this blog post, none provides deduplicated citation links between publication families. The Lens informed us that they may provide deduplicated links in the future.
Dimensions, Europe PMC, and the Lens treat preprints in the same way as journal articles. They therefore fully meet our sixth recommendation, resulting in two stars. Web of Science makes a sharp distinction between preprints and journal articles by including preprints in a separate Preprint Citation Index and by presenting citation information separately for citations from preprints and citations from journal articles. Moreover, citations from journal articles are shown more prominently than citations from preprints, except in the Preprint Citation Index, where citations from preprints are displayed more prominently. This seems inconsistent and may confuse users. Because of this, we have awarded only one star to Web of Science. Scopus has not been awarded any stars. The document search feature in Scopus enables users to search for journal articles, but not for preprints. This is a highly arbitrary distinction between these two publication types. Scopus also excludes citations from preprints from the citation statistics it provides.
The above table shows that there is ample room for bibliographic databases to improve their indexing of preprints. Users of bibliographic databases will increasingly be interested in preprints, in addition to journal articles and other more traditional publication types. We advise users interested in preprints to make sure they use a database that serves their needs, and we hope the above table will help them make the right choice.
Improving indexing of preprints - The need for joint action
Bibliographic databases are part of a larger ecosystem of infrastructures for scholarly publishing. To allow bibliographic databases to improve their indexing of preprints, other actors in this ecosystem also need to take action.
First of all, preprint servers need to make available as much preprint metadata as possible. Most preprint servers register DOIs for preprints at Crossref. This enables them to make preprint metadata available by depositing the metadata to Crossref. Preprint servers are indeed submitting metadata to Crossref, but there is still considerable room for improvement. Metadata submitted to Crossref can be harvested by bibliographic databases, helping them to provide comprehensive metadata for the preprints they index. One database, Scopus, informed us that to obtain high-quality preprint metadata it needs to scrape the metadata from the websites of preprint servers. In a well-organized infrastructure ecosystem, there should be no need for web scraping.
Second, journal publishers need to add links from the articles they publish in their journals to the corresponding preprints. These links can be included in the article metadata that publishers deposit to Crossref. Unfortunately, with a few exceptions (Copernicus, eLife), publishers are doing a poor job in linking journal articles to preprints. Publishers need to work together with the providers of manuscript submission systems (Editorial Manager, Open Journal Systems, ScholarOne, etc.) to improve this.
Third, preprint servers and peer review platforms need to work together to allow bibliographic databases to harvest links between preprints and peer reviews. Ideally, each peer review should have its own DOI, and peer review platforms should include links from peer reviews to the corresponding preprints in the metadata they submit to the DOI registration agency (Crossref, DataCite). For peer reviews without a DOI, other ongoing infrastructure initiatives, in particular the COAR Notify Initiative, DocMaps, and Sciety, offer promising approaches for linking preprints and peer reviews.
Outlook
Without doubt, the adoption of preprinting will continue to increase in the coming years. Preprint peer review will also grow in importance, especially in the life sciences. As a result of the ongoing transition toward a culture of open science, researchers will increasingly share their work in an early stage, prior to peer review. Sharing intermediate results, such as research plans (preregistration), will also become more common. In addition, the boundaries between different types of publications will get increasingly blurry. For instance, eLife, Peer Community In, and the various F1000 platforms essentially represent hybrids of preprinting and traditional journal publishing. Their popularity will make the distinction between preprints and journal articles more and more fuzzy.
To keep up with these developments, bibliographic databases need to innovate. This is the case in particular for Scopus and Web of Science, the two oldest databases. Scopus has a selective coverage policy. The same applies to the Core Collection of Web of Science. Rather than trying to cover as many journals as possible, these databases cover only journals that are considered to meet certain quality standards. This philosophy of selectivity is difficult to maintain in a world in which sharing of non-peer-reviewed research results is not only becoming more accepted, but is even gradually becoming the norm. It seems essential for Scopus and Web of Science to work toward providing a more comprehensive coverage of the scholarly literature. Indexing of preprints is an important step in this direction.
We expect users of bibliographic databases to increasingly move away from the idea that a database should filter the scholarly literature for them by indexing only high-quality content. Users will instead expect a database to offer tools that allow them to filter the literature themselves. This means that bibliographic databases need to provide a comprehensive coverage of the literature and need to help users answer questions such as: Does this publication present the final results of a research project or does it report provisional intermediate findings? And what kinds of quality checks has the publication undergone? Has it been peer reviewed? And if so, are the peer reviews openly available? Or is there other information available about the nature of the peer review process? And have data and code underlying the publication been made openly available? Enabling users to obtain the best possible answers to these types of questions is the new holy grail for bibliographic databases.
We thank Dimensions, Europe PMC, the Lens, Scopus, and Web of Science for their feedback on a draft version of this blog post. We are also grateful to Iratxe Puebla, Martyn Rittman, and several colleagues at the Centre for Science and Technology Studies (CWTS), Leiden University for their feedback.
EDIT [2023-02-21]: Some minor remarks were added regarding the Lens (they're adding preprint links and may provide deduplicated links).
Copyright © 2023 Ludo Waltman, Nees Jan van Eck. Distributed under the terms of the Creative Commons Attribution 4.0 License.







