
In November of 2022, the Research Software Alliance (ReSA) and the Netherlands eScience Center organized a two-day international workshop titled “The Future of Research Software.” In the workshop, funding organizations joined forces to explore how they could effectively contribute to making research software sustainable. The workshop had many participants from all continents and was a huge success. A tangible outcome was a draft of the "Amsterdam Declaration on Funding Research Software Sustainability." Note that the workshop focused on research software (where the primary purpose of the software is research-related), not all software used in research, and this blog post similarly focuses on research software.
Rob van Nieuwpoort, one of the authors of this blog post, gave a talk at the workshop where he tried to define the roles of research software. He did this at a relatively high level and from the point of view of a researcher in a discipline (i.e., typically not a computer scientist), with the goal of making this understandable for funders and policymakers, who are experts on science policy but may not know much about research software. In an effort to explain what research software is all about, he tried to highlight its huge variety. Again, the point was not to create an exhaustive classification but to explain research software and its importance (and thus the value of sustaining such software) to a broad audience of non-experts.
After this talk, Dan Katz and Rob had a nice discussion about the value of defining the roles of research software. One of the things discussed was whether Rob's initial classification (see the presentation slides) actually is the best one, and if we were missing any classes. Dan suggested collecting input from the community via social media and then writing a blog post (this one) on this topic. So, without further ado, here is our attempt to define the roles of research software, illustrated with examples.
Research software is a component of our instruments
Software is an integral component of many instruments used in research. Examples include software in a telescope, particle accelerator, microscope, MRI scanner, and other instruments. Note that the word “instrument” should be interpreted broadly: there are many different types of (physical and virtual) instruments in different research disciplines. In the social sciences, for example, survey software can be considered an instrument, where a component could be user-facing software to collect data (apps, websites, etc.)
The purpose of research software as a component in our instruments can include acquisition, methods to stream or upload experimental data, data cleaning, and processing. Or more generally, research software components organize, serve, and provide access to data [suggested by Kelle Cruz]. Other examples of the functionality of software components in instruments include monitoring and control, calibration, imaging, etc.

Research software is the instrument
Sometimes the software itself is the instrument: it generates research data, validates research data, or tests hypotheses. This includes computational methods or models and simulations, such as climate models, agent-based models in the social sciences, hardware simulators, etc. In general, we have some idea about how the world works, and we design or use software to test that against some fusion of direct measurement and basic underlying analytical models [suggested by Chris Hill].
This class of research software can be an expression of a new idea, method, or model. In other words, it is a creative expression. It can be considered a "uniquely actionable form of knowledge representation," [suggested by Tom Honeyman] or an “interoperable version of method papers.” [suggested by Mirek Kratochvíl]. A computational model or simulator is an experimental tool to assess and improve our understanding, but also literally a "proof of concept." So they are instruments, workbenches, and experimental proofs of our scientific statements [suggested by Martin Quinson].
Research software as an instrument also includes platforms for generating or collecting data (e.g., survey tools in the social sciences), or online experimental platforms. Sometimes this research software can be wielded more freely by the researcher, for example, search and annotation tools that allow researchers to query and enrich data [suggested by Maarten van Gompel]. In this case, software supports interaction with data, allowing researchers to explore the data in new ways, generating new data sets.
Examples: In the biochemistry realm, software is used for modeling molecules for use in a next-gen diagnostics or therapeutics: we want to design some molecule in software with some characteristics that we can experimentally validate later. Other examples include designing and modeling medical devices, devices to help with environmental monitoring or cleanup, CAD tools, or designing new compute hardware [suggested by Jonathan Romano].

Research software analyses research data
Research software is important for analyzing research data as well. Sometimes this analysis is automated, such as data access and processing, model fitting, filtering, aggregation, and search. In other cases, the software supports and facilitates researchers in doing the analysis, for example, for qualitative data analysis. Other examples of software-supported analysis include natural language processing pipelines, data science tools (a concrete example could be ESMValTool), software notebooks (Jupyter), machine learning pipelines for classification and anomaly detection, etc.

Research software presents research results
Research software can also be used to explain data, or to present research results. Scientific visualizations are a prime example, but so is software with the specific purpose of generating plots in research papers, or interactive visualizations on websites. Note that software is used to disseminate research in general, not only to researchers but also to a broader audience. It also is applicable for transitioning the research from academia to industrial applications. Having well-written software can help encourage the adoption of the research software in companies [suggested by Ian McInerney].
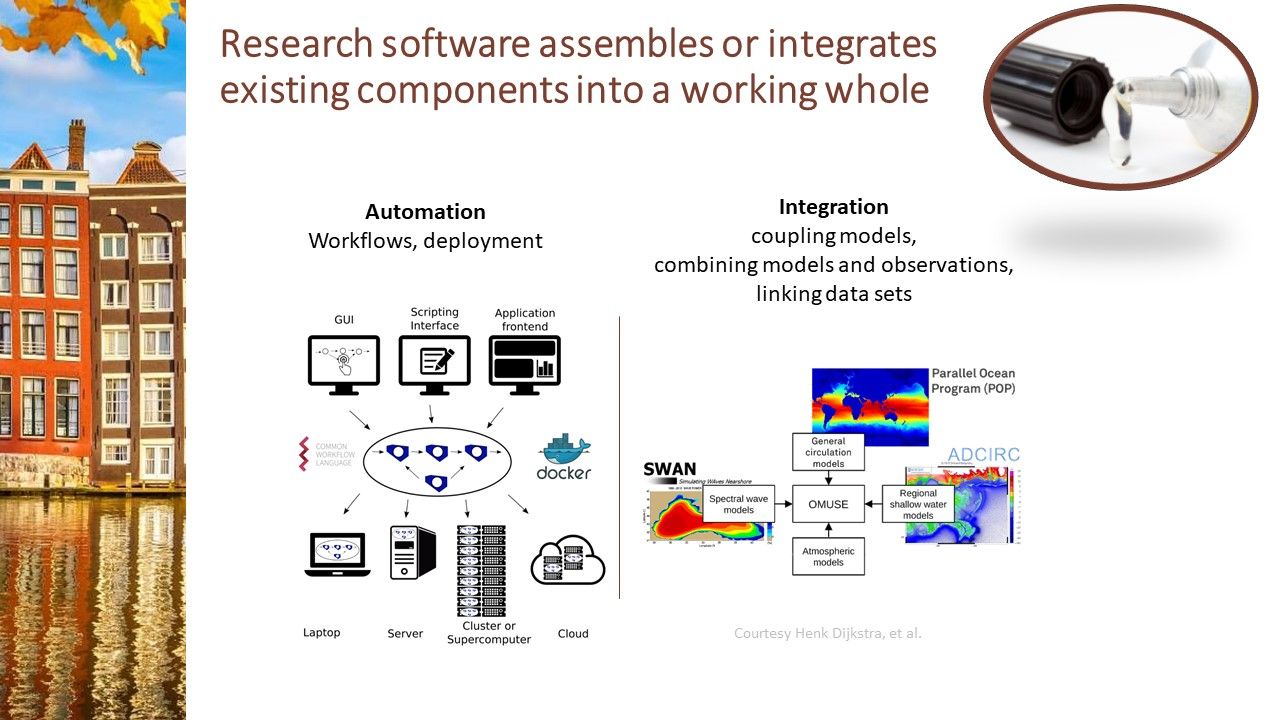
Research software assembles or integrates existing components into a working whole
[suggested by Mark Hoemmen] An important, but often overlooked purpose of research software is integration and automation. This includes making efficient use of infrastructure, as well as repetition and scaling of experiments or analysis. A growing number of experimental systems (more than just an instrument) need to be run simultaneously in an orchestrated manner [suggested by Ian Cosden]. The research software performing these tasks is becoming ever more complex. Software supporting workflows, for example, can help in structured and reproducible automation and repetition.
Another form of integration is the coupling of different computational models, combining computational models with data-driven models (AI-based surrogate models), potentially while assimilating observational data. Consider the construction of digital twins, for example. Specifically designed research software in the form of model-coupling frameworks can facilitate this, helping with the coupling and deployment, but also for example with the propagation of uncertainty quantification between models.
A third class of integration software also deserves attention: Python or shell scripts that automate things, connect components and tools, or let data flow between different executables. Note that small scripts especially often are not adequately tested and maintained, even though they are critical to reproducing scientific results.

Research software is infrastructure or an underlying tool
[suggested by Jed Brown] In all areas of research, there is a role for “infrastructure software,” which sometimes is not unique to research-oriented organizations, but is heavily relied upon [suggested by Jordan Perr-Sauer]. Some lower-level software was created specifically for research (i.e., known as research software,) while other software infrastructure is meant for general utility and happens to be important for research (i.e., software in research.) Examples include compilers and programming languages, generic software libraries, code repositories, data repositories, and open source software in general. (Note that this is discipline-dependent, as a compiler would likely be research software within computer science research on programming languages.) As described by the Ford Foundation: “Free, publicly available source code is the infrastructure on which all of digital society relies. It is vital to the functioning of governments, private companies, and individual lives.” (See Roads and Bridges: The Unseen Labor Behind Our Digital Infrastructure / Ford Foundation.) It is equally vital to research.
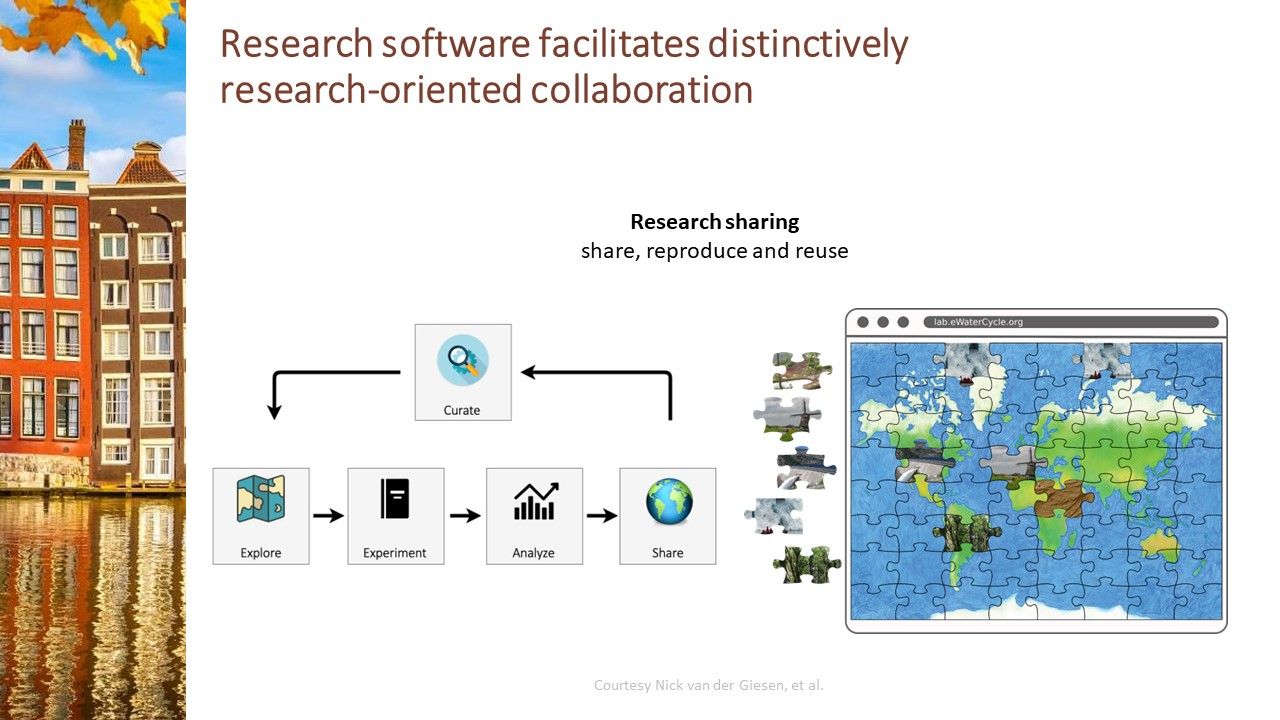
Research software facilitates distinctively research-oriented collaboration
[suggested by Lee Liming] A lot of software and services have been specifically designed to facilitate research-oriented collaboration. Although sometimes not considered research software as such, this class certainly is important in research, and deserves a mention. With research becoming more and more open, team-based, interdisciplinary, collaborative, and inclusive (e.g., citizen science,) the usage and value of software facilitating collaboration is exploding. Examples include platforms to collaborate on software (GitHub, GitLab, Stack Overflow,) papers (Overleaf, ORCID, Zotero,) data (Zenodo, HUBzero, CyVerse,) computing (SciTokens, SciGaP,) software that is employed in citizen science [suggested by Chris Erdman] and many others.
Summary
It is clear that there are many different types of research software, fulfilling many different roles and functions. This huge variety makes it hard to come up with a good classification that captures all aspects and does justice to all the hard work done by the developers of the software. Nevertheless, we hope that we have succeeded in proving a bit more insight into the value of research software, the importance of sustaining said software, and recognizing the people involved in developing the software.
You can contact us at R.vanNieuwpoort@esciencecenter.nl and d.katz@ieee.org.
Copyright © 2023 Rob van Nieuwpoort, Daniel S. Katz. Distributed under the terms of the Creative Commons Attribution 4.0 License.





{kind=link}