
Data Processing and production: Jamie Diprose
Cross-posted from the COKI blog.
There is a lot of lip service paid to the idea of diversity in scholarly publishing and often diversity of language is used as an example. The Helsinki Initiative is one example of an explicit call for multilingualism and the Jussieu Call for bibliodiversity, while it does not explicitly mention language, is an implicit criticism of anglo-centric publishing. The UNESCO Open Science Recommendation states that
…open science should embrace a diversity of knowledge, practices, workflows, languages, research outputs and research topics that support the needs and epistemic pluralism of the scientific community as a whole…
The State of the Internet’s Languages Report extends this to the internet as a whole showing how these issues extend far beyond scholarly communications.
But while the groups that work actively in languages other than English have been making this point consistently and forcefully, it has had limited traction in the scholarly anglophone literature. A few articles have implemented or suggested indicators that track language diversity but there appears to be relatively few examples of analyses at scale (for a nice counter-example see Kulczycki et al 2018 and 2020). To address this gap, we have mapped the 122 million objects in Crossref up to the end of May 2022 to languages (based on titles and abstracts, where available) and done an initial analysis. The results are a mix of the expected and surprising.
Languages in the Scholarly Literature
We took a quick approach to mapping the languages that can definitely be improved (see below for details). We would welcome suggestions and contributions on how to improve the methodology, with an eye towards including this as a standard parameter for scholarly outputs. Obviously all of this analysis is limited to outputs in the Crossref metadata dataset, which will result in some bias, both against publications without a DOI as well as publications with DOIs from different registrars, with the Chinese National Knowledge Infrastructure (CNKI) being an important example.
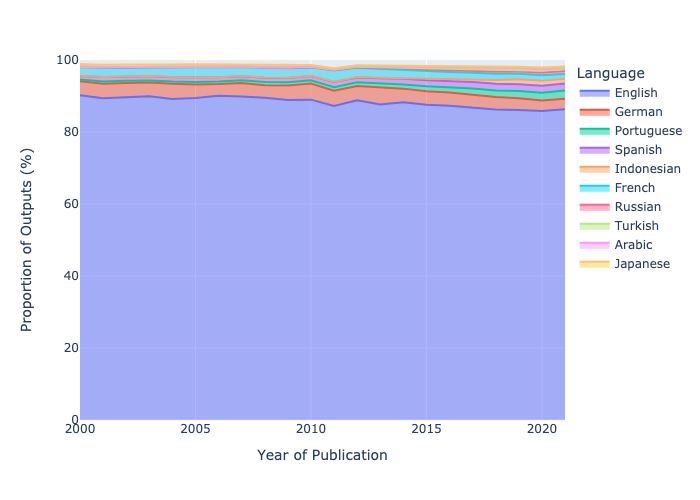
Not surprisingly, English dominates the literature (although with a slowly dropping proportion) with other European languages following including German, French, Spanish and then Portuguese, with Bahasa Indonesian as the next largest language. Spanish and Portuguese grew strongly over the period with Portuguese growing from around 7,000 outputs captured in 2000 to over 150,000 in 2021, reflecting the rise of Brazil as a research powerhouse, and the effectiveness of SciELO as a dissemination platform over that period. Indonesian shows massive growth, probably in part reflecting improved coverage of Crossref metadata over this period along with the massive growth of Indonesian publishing efforts.

The types of content are different as well with German having a much higher proportion of book chapters and books (and French having a large number of component DOIs) and the large number of preprints (posted-content) in Indonesian. The latter example also illustrates issues with the data collection. After INA-Rxiv closed to new submissions in 2020 and submissions moved to RINarxiv this content was not assigned Crossref DOIs and therefore will disappear from our analysis. These differences between languages are likely to have complex effects on the analysis of qualities of the content, particularly open access and citations. In most of this analysis we’ve left all types of content in, but the processed dataset is split out by Crossref type so you can look more closely at those issues!
Open Access and Languages
Open access shows substantial differences across languages. Perhaps even more importantly, our ability to classify open access types is leading to issues across different languages. Indonesian is a great example. Currently we use DOAJ as the marker of a “completely OA journal” (and we differ from Unpaywall in this at the moment). Many Indonesian journals are not in DOAJ and therefore show as “hybrid”. Unpaywall is also not always able to pick up license information so full OA journals that are not in DOAJ may also get characterized as “bronze”. In Portuguese it is likely that a large proportion of “hybrid” is actually fully OA journals published through SciElO. Categories of open access publishing in Hungarian, Polish, Turkish and many other languages are also likely to need closer examination. We used DOAJ to identify non-APC journals as well and this is likely undercounting this category for Indonesian, Turkish, Portuguese and Spanish outputs.
Nonetheless, we observe high proportions of articles in non-APC journals in Spanish and Portuguese (attesting to the success of the diamond OA model in Latin America), as well as in a number of other languages, including Nordic languages, many Eastern European languages, and others. Overall, when looking at 2020-2022, for English articles in DOAJ journals, 21% are in non-APC journals, but for articles in languages other than English, this percentage is a massive 86%. Non-APC models appear to dominate the landscape for non-English full OA journals. And amongst English language articles in OA journals (as defined by registration in DOAJ) the APC model definitely dominates. As is often the case, innovation rooted in community needs is more common away from traditional centres of prestige.
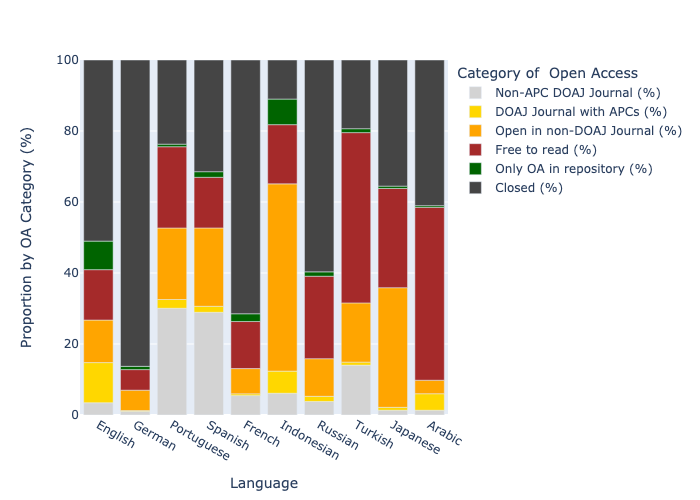
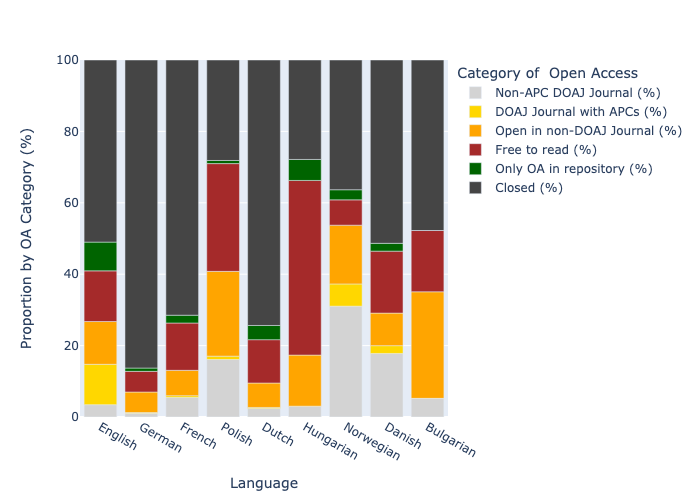
Some countries with high levels of open access in English have comparatively low levels in the local language. This is the case for the Netherlands and to some extent France and Germany. This is most likely related to disciplinary differences in what is published in English (with a bias towards STEM and higher levels of OA) vs local language (with a bias towards HSS subjects). By contrast Nordic languages and Norwegian in particular show high levels of open access with an emphasis on APC-free OA journals, likely as a result of local initiatives to fund the conversion of national language journals (which tend to focus on HSS) to open access. The Hrčak central portal providing support for Croatian journals is another example with Croatian also showing a similar pattern.
Missing what you don’t look for and next steps
In this dataset outputs in languages other than English remain a fairly small proportion, less than 20%, of the total. But within that segment is a far greater diversity of practice, and substantial differences to the English majority. If we are looking for examples of different practice, and successes beyond the “standard” models of APC-OA publishing, hybrid and transformative agreements there is a wealth of case studies here. Pointing to Latin America has long been a go-to exemplar, but Eastern Europe, Scandinavia and Indonesia are rich in examples. And we have barely scratched the surface here.
Similarly, just looking at that surface has revealed real issues with the way we categorise open access publishing that do not reflect the realities on the ground in settings beyond Europe and North America. As with so many aspects of scholarly practice and evaluation, you can’t find what you can’t look for. We are providing the language mapping and analysis datasets for others to dig deeper, and ideally improve on our methodology.
There are obvious improvements that could be made to the language mapping, including determining language for titles (of which there may be more than one) and abstracts separately, applying an acceptance threshold rather than just selecting the top scoring language, and ultimately refining the language model to work specifically on scholarly content. Again, we hope that sharing the dataset will prompt others to look at how to improve on the process.
Ultimately, we believe that including a language analysis might be something that can be easily included as part of any discussion of scholarly communications. We could make this possible in a matter of months, not years, if we work collectively. And in doing so we will provide new ways to look at the diversity of scholarly publishing to everyone’s benefit.
COKI Language Dataset Methodology
Constructing the Language Mapping
A subset of the COKI Academic Observatory Dataset, which is produced by the Academic Observatory Workflows codebase [1], was extracted and converted to CSV with Bigquery and downloaded to a virtual machine. The subset consists of all publications with DOIs in our dataset, including each publication’s title and abstract from both Crossref Metadata (as of 28 May, doi20220528) and Microsoft Academic Graph (the final dump of 6 December 2021 as available in doi20220528). The CSV files were then processed with a Python script. The titles and abstracts for each record were pre-processed, concatenated together and analyzed with fastText. The titles and abstracts from Crossref Metadata were used first, with the MAG titles and abstracts serving as a fallback when the Crossref Metadata information was empty. Language was predicted for each publication using the fastText lid.176.bin language identification model [2]. fastText was chosen because of its high accuracy and fast runtime speed [3]. The output dataset [4] consists of DOI, title, ISO language code and the fastText language prediction probability score. The dataset is also publicly viewable on Google BigQuery (you may need a free Google Cloud account to view this).
Analyzing the Crossref subset by language
The language mapping dataset was joined to the Academic Observatory Dataset [1] and queried for open access, Crossref output type and citation characteristics (see graph_data.sql in the coki-language repository), and downloaded and saved as CSV (output_graphs/downloaded_data.csv). The downloaded data was processed using a python script (graphs.py) to generate the graphs in this post. Open access status was derived from Unpaywall data as defined in the relevant Academic Observatory query with the exception of “diamond” which was determined by querying a local copy of the DOAJ data dump for journals which are registered as having no APC (see graph_data.sql line 20 in the coki-language repository).
Data
The COKI Language Dataset is publicly accessible in BigQuery in the following two tables:
Code
COKI Language Detection [5]: https://github.com/The-Academic-Observatory/coki-language
Academic Observatory Workflows: https://github.com/The-Academic-Observatory/academic-observatory-workflows
References
- Richard Hosking, James P. Diprose, Aniek Roelofs, Tuan-Yow Chien, Rebecca N. Handcock, Bianca Kramer, Kathryn Napier, Lucy Montgomery, & Cameron Neylon. (2022). Academic Observatory Workflows (2022.03.0). Zenodo. https://doi.org/10.5281/zenodo.6366695
- https://fasttext.cc/docs/en/language-identification.html
- https://modelpredict.com/language-identification-survey
- James P. Diprose, & Cameron Neylon. (2022). COKI Language Dataset (2022-06-13) [Data set]. Zenodo. https://doi.org/10.5281/zenodo.6636625
- James P. Diprose, Bianca Kramer, & Cameron Neylon. (2022). COKI Language Detection (v1.1.0). Zenodo. https://doi.org/10.5281/zenodo.6648251
Copyright © 2022 Cameron Neylon, Bianca Kramer. Distributed under the terms of the Creative Commons Attribution 4.0 License.







{kind=link}